# 背景

ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。
ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
# 开源地址
https://github.com/THUDM/ChatGLM3
# 部署
# 视频演示
我做了一个简单的 DEMO 演示视频,可以先进行观看
https://www.bilibili.com/video/BV1Lg4y1k7Yy/
# 硬件需求
要在本地机器完全单机离线部署完整的 ChatGLM 3,你需要至少 13GB 显存的 GPU,整个 ChatGLM3-6B 的模型文件权重大小为 13G,当然也可以对模型进行量化,使得在小于 6GB 显存的显卡上也能运行,代价是微弱的性能损失。
# 软件需求
- 操作系统:Windows 10/11, Linux, macOS (MPS 加速需要 >= 12.3)
- Python:>=3.10
注意:在 macOS 上支持使用 MPS 后端的 AMD 显卡和 Apple Sillicon 的加速,配置教程会在后文给出
# 部署
- 创建虚拟环境并且进入虚拟环境
| |
- 根据 PyTorch 官网 安装 PyTorch,正确安装才能开启 GPU 加速
| |
- 克隆仓库并安装依赖
| |
transformers 库版本应该 4.30.2 以及以上的版本 ,torch 库版本应为 2.0 及以上的版本,以获得最佳的推理性能。
- 手动下载模型,如果你有一个良好(魔法)的网络环境,可以跳过这一步,直接到第 5 步,模型会在那个阶段自动下载。
| |
- 运行 DEMO
| |
- 如果你的显存不达到要求,你可以略微修改代码,量化模型,或者在CPU上运行,当然你可以跳过这一步。
使用代码编辑器打开 composite_demo 下的 client.py文件,定位到 150 行,以下是原始代码
| |
在.eval前面加上量化方法,如下
| |
使用 4-bit 量化的情况下,尽管会带来一定的性能损失,但仍然能够进行自然流畅的生成。
或者你可以使用 CPU,但是推理速度会更慢,需要大概 32GB 内存
| |
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM3-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
目前在 macOS 上只支持从本地加载模型,并使用 mps 后端
| |
- 一切就绪,运行 DEMO 服务
| |
如果一切工作正常,且你已经下载好了模型,那么将会弹出一个交互式的网页,你可以在里面进行对话等操作。
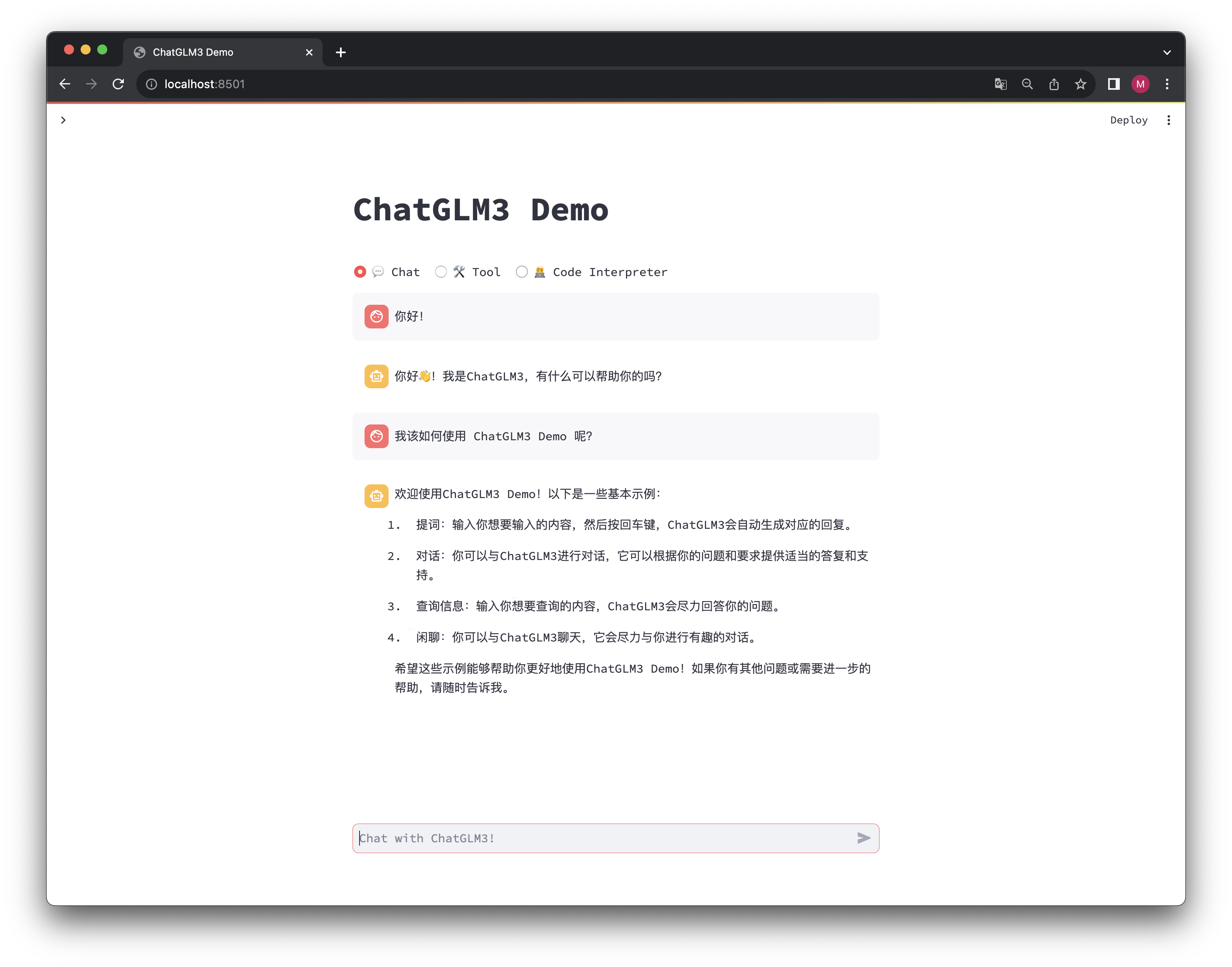
# 结语
如果你在部署过程中有任何问题,请不要犹豫在下面的评论区提问,你可以发送图片,以便更好的定位问题。